The Testing Funnel: Validating LLVM at Scale
EuroLLVM 2026 Keynote
Last week I delivered the second keynote talk at EuroLLVM in Dublin, titled “The Testing Funnel: Validating LLVM at Scale” (slides). I got a lot of positive feedback, and it generated a lot of good discussion after the talk!
I quickly added a roundtable onto the afternoon schedule to discuss it further. I think Jonas Devlieghere took notes (thank you!), and I hope he posts them soon after a light editing pass. There’s only so much you can fit into one 45min talk, so I decided to sit down and write this post to capture and share more of my thoughts on this topic.
Talk Recap
To quickly restate the thesis, it’s that we need significant investment in public LLVM infrastructure that goes beyond premerge testing, which only started producing fast, clean results in the last 1.5 years. Currently, many folks in our community spend a lot of time chasing regressions from changes to llvm-project, and if we don’t improve our processes, we’re going to be stuck doing that for a while.
These were some of my major points:
-
LLVM is foundational: LLVM is widely adopted across industry by many organizations and put to many purposes. Even small changes ripple throughout the industry, uncover implicit dependencies, and manifest as regressions, which create work for both downstream and upstream.
-
Requirements will exceed premerge testing capacity: The correct, conventional industry wisdom is to test all the requirements you really care about before you push changes to your main development branch. However, LLVM is an outlier in that its requirements are ever-growing, and its testing resources are scarce and slow-growing. This means there’s always a gap between what our downstreams care most about and what we can afford to test in upstream LLVM.
-
Testing funnel: Because of resource constraints on premerge tests, LLVM, like many projects, uses a multi-layered testing strategy I call the “testing funnel”. The width of the funnel corresponds to the throughput of changes you can run in that layer at any given time. Local testing scales with developers, premerge currently handles ~109 changes landed a day, hourly buildbots cycle 24 times daily, and expensive release qualification tests may run for multiple days. This metaphor also applies to projects like Rust that use merge queues to batch changes together to run expensive tests before merging them to main.
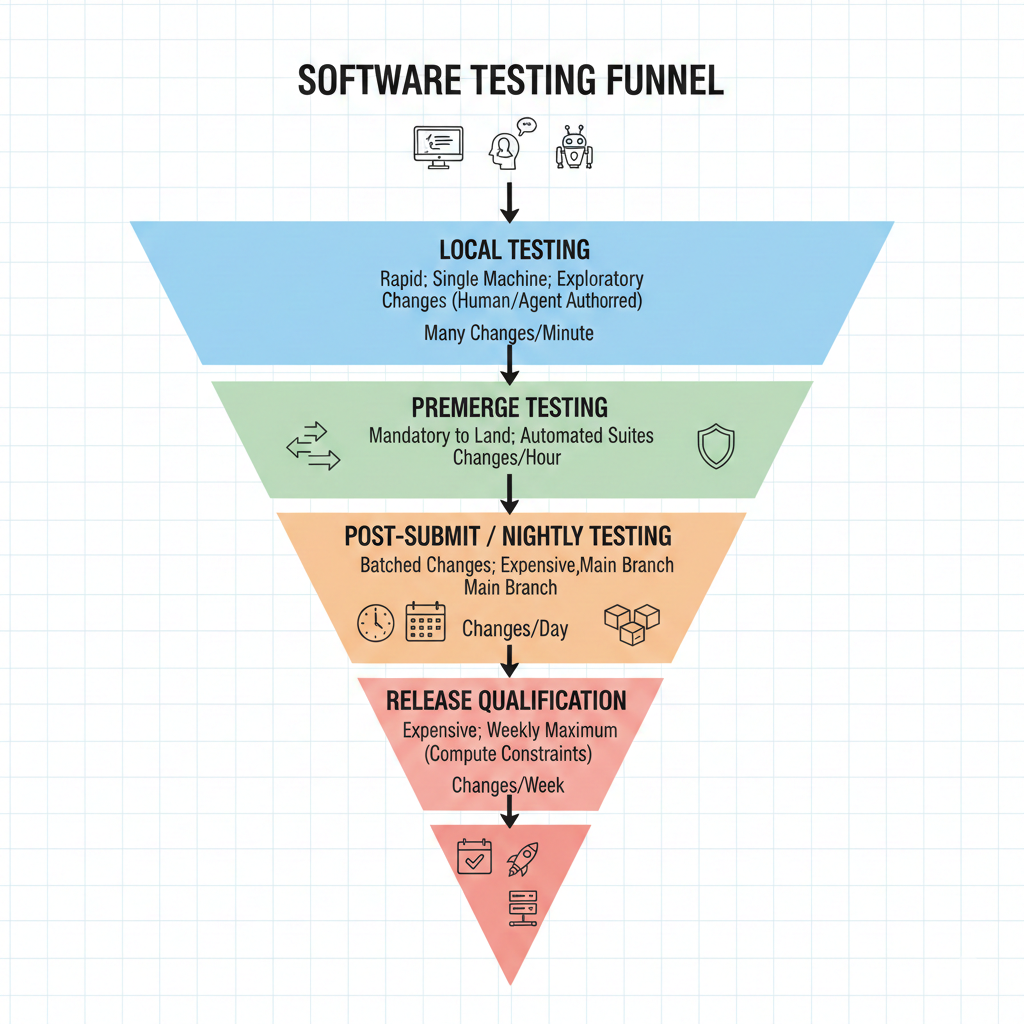
My main conclusion was that, given we have post-merge tests, both upstream and downstream, and the purpose of CI is to fail, we should be prepared for it to fail! The not rocket science rule of software engineering is powerful, but it has its limits.
If we expect regression reports, then we should invest in automated root cause analysis tools to optimize the reporting process. Many analysis tools exist, such as git bisect, cvise, llvm-reduce, opt-bisect, etc, but they all have to be driven by an experienced operator. Even when the tools work, their results have to be shared as unstructured text. Having public, shareable links to analysis artifacts is really powerful. We should run analysis-as-a-service tools so that we can create shared truth.
I outlined three principles for good infrastructure:
- Automation: Good infrastructure is automated. This is a no-brainer, but more is better. Ask yourself, do you trust every member of your compiler team to pilot git bisect or cvise? Shouldn’t that be automatic?
- Shared truth: Linkable artifacts are really powerful. There is a big difference between an issue report, and data and visuals from official project infrastructure.
- Static metrics: It’s often better to use proxy metrics that are stable, deterministic, and reproducible, so long as they predict the true metric monitored somewhere else less often.
Hopefully this post inspires others to help build more of these tools. Fortunately, we already have several working examples of good infra that we can draw lessons from and maybe fund more thoroughly.
Existing tools
Here are three examples of tools that demonstrate the principles in action.
llvm-compile-time-tracker.com
llvm-compile-time-tracker demonstrates all three principles. Most obviously, this tool is automated. It is triggered by pushing specially named branches to monitored GitHub repos.
What’s more interesting is that it tracks instructions retired as a proxy for compile time, a static metric. Anyone who’s done performance engineering knows cache is king and memory access patterns matter. However, a deterministic, low-noise metric that correlates with wall time is far more useful than a noisy one you can’t act on.
Finally, every data point is a linkable URL, which creates shared truth. The long-term-trend graph shows years of LLVM compile time moving in the right direction, and anyone in the community can link to a regression, point to a specific commit, or settle an argument with data. That’s leadership through metrics. Credit to Nikita Popov for building and maintaining it!
llvm-opt-benchmark-nightly
llvm-opt-benchmark-nightly is another static metrics tool. It builds a corpus of C, C++, and Rust and tracks compiler pipeline stats — how often key transforms fire — diffed against your baseline. Knowing a change causes a target transform to fire more tells you you’re moving in the right direction, even when wall-time differences are too noisy to measure. Running this requires rebuilding LLVM and the whole benchmark corpus at every baseline revision you care about, which requires significant backend compute. Thanks to Yinwei Zheng for creating and running it.
LNT
LNT (LLVM Nightly Test) is classic performance monitoring infrastructure. It’s public and automated, although it doesn’t track static metrics. This is the kind of infrastructure that catches regressions without any human driving it. Today, the main instance (lnt.llvm.org) has been down for months, but there is another instance at cc-perf.igalia.com. There is also interest in a rewrite. Thanks to Luke Lau and Louis Dionne for picking up the reboot.
What’s Next?
I don’t have complete notes from the roundtable, but these were some of the ideas I left with. Nobody committed to do any of these things and pretty much all of them require an RFC, but before you do that, you have to have an idea.
-
Establish metrics and policies for buildbots: If you’ve ever landed changes to LLVM, then you’ve received spam from our buildbot. We’re sorry. We need to gather metrics on the speed and reliability of our bots and set baseline policies for what we expect from buildbot operators. When a bot fails to comply, we should silence it. Notifying contributors about post-commit failures is a service we offer to platforms with limited testing resources, not an obligation — and if we’re going to spend limited contributor attention on those emails, the bots should meet a minimum quality bar.
-
Set up automated root-cause tools: This was my thesis from the talk, so I hope this actually happens. If there is any analysis-as-a-service by next year, I will call it a win. During the roundtable, we discussed bisecting failing builds directly on the existing build workers, but there are many reasons why this might be impractical, flaky tests and flaky build infrastructure being the first. We talked a lot at the roundtable about ELFShaker and manyclangs. Personally, I would like to set this up locally and create a personal repository of pack files for a multicall driver build of LLVM (
LLVM_TOOL_LLVM_DRIVER_BUILD). This would form the basis of a simple root cause tool. Not to be glib, but this is well-scoped enough that an LLM coding agent could prototype it. Bisection is a well-understood problem, and one could use the Remote Execution API to launch a bunch of interestingness tests in parallel to quad-sect or further parallelize bisection. -
Add small execution tests to premerge: LLVM has pushed the idea of FileCheck tests about as far as it can go. At this point, it’s reasonable to consider adding feature-targeted execution tests in-tree to run as part of the premerge testing pipeline. “Feature” here refers to individual features like
i128math, exception handling, calling conventions, and other tests that are small and fast. In fact, we already have tests like this inllvm-test-suite/SingleSource, but they are not part ofllvm-project. Single-source execution tests are inexpensive to run (if you have the right hardware or simulator), but they are often impossible to debug remotely. If we have tools to dump the assembly or IR diff when the test fails, that would go a long way to address concerns about actionability from developers. It’s also awkward that these live out of tree, and if we want developers to add integration tests along with the changes they are making, we’d have to reconsider that choice. Execution tests are actually small relative to FileCheck tests. SingleSource is 31MB, while llvm/test is 1.1GB.
Final thoughts
I still tend to focus on the C/C++ application programming ecosystem, since that’s where my experience is, but I suspect that most of these ideas carry over to MLIR, Flang, Python EDSL DL frontends (Triton, PyTorch, etc), and Rust (yes, not an LLVM project, but part of the “LLVM native code ecosystem”).
Anyway, hopefully you find this “testing funnel” metaphor useful, and it helps you talk about making better tradeoffs in your CI pipeline instead of getting caught in a never-ending tug of war between “all requirements must be tested” and “these testing requirements are onerous”. Instead, mention this metaphor and ask questions like:
- Is this test in the right layer? Is this test too expensive to run this early?
- Does this test produce actionable results? How can I make the results of this test more actionable?
- How much confidence does this test give me that my product works?
- How do I craft a test that gives me the same confidence for 10x less cost?
There’s been a lot of hullabaloo about how great LLM coding agents are, but one of the consistent findings has been that LLMs need clear test and validation criteria to create working solutions. But, if the agents need fast CI that produces actionable logs, don’t human developers deserve that too? It doesn’t seem like a fair comparison to require developers to boil the ocean before making a small change, and then talk about how fast LLMs are at building things when the agents’ code often doesn’t make it to production. We should instead realize that humans also benefit from being able to make small changes, observe the effects, and iterate. Software development is built on feedback loops, so if you want to focus on the bigger picture, focus on that feedback loop.